KMP字符串比较算法原理通俗易懂超级简单
日期:2019-11-20
来源:程序思维浏览:1630次
大多数据结构课本中,串涉及的内容即串的模式匹配,需要掌握的是朴素算法、KMP算法及next值的求法。下面我给大家介绍一下KMP的算法原理:
一、问题描述
给定一个主串S及一个模式串P,判断模式串是否为主串的子串;若是,返回匹配的第一个元素的位置(序号从1开始),否则返回0;如S=“abcd”,P=“bcd”,则返回2;S=“abcd”,P=“acb”,返回0。
二、朴素算法
最简单的方法及一次遍历S与P。以S=“abcabaaaabaaacac”,P="abaabcac"为例,一张动图模拟朴素算法:

这个算法简单,不多说,附上代码
#include<stdio.h>
int Index_1(char s[],int sLen,char p[],int pLen){//s为主串,sLen为主串元素个数,p为模式串,pLen为模式串的个数
if(sLen<pLen)return 0;
int i = 1,j = 1;
while(i<=sLen && j<=pLen){
if(s[i]==p[j]){i++;j++;}
else{
i = i-j+2;
j = 1;
}
}
if(j>pLen) return i-pLen;
return 0;
}
void main(){
char s[]={' ','a','b','c','a','b','a','a','a','a','b','a','a','b','c','a','c'};//从序号1开始存
char p[]={' ','a','b','a','a','b','c','a','c'};
int sLen = sizeof(s)/sizeof(char)-1;
int pLen = sizeof(p)/sizeof(char)-1;
printf("%d",Index_1(s,sLen,p,pLen));
}
三、改进的算法——KMP算法
朴素算法理解简单,但两个串都有依次遍历,时间复杂度为O(n*m),效率不高。由此有了KMP算法。
一般的,在一次匹配中,我们是不知道主串的内容的,而模式串是我们自己定义的。
朴素算法中,P的第j位失配,默认的把P串后移一位。
但在前一轮的比较中,我们已经知道了P的前(j-1)位与S中间对应的某(j-1)个元素已经匹配成功了。这就意味着,在一轮的尝试匹配中,我们get到了主串的部分内容,我们能否利用这些内容,让P多移几位(我认为这就是KMP算法最根本的东西),减少遍历的趟数呢?答案是肯定的。再看下面改进后的动图:
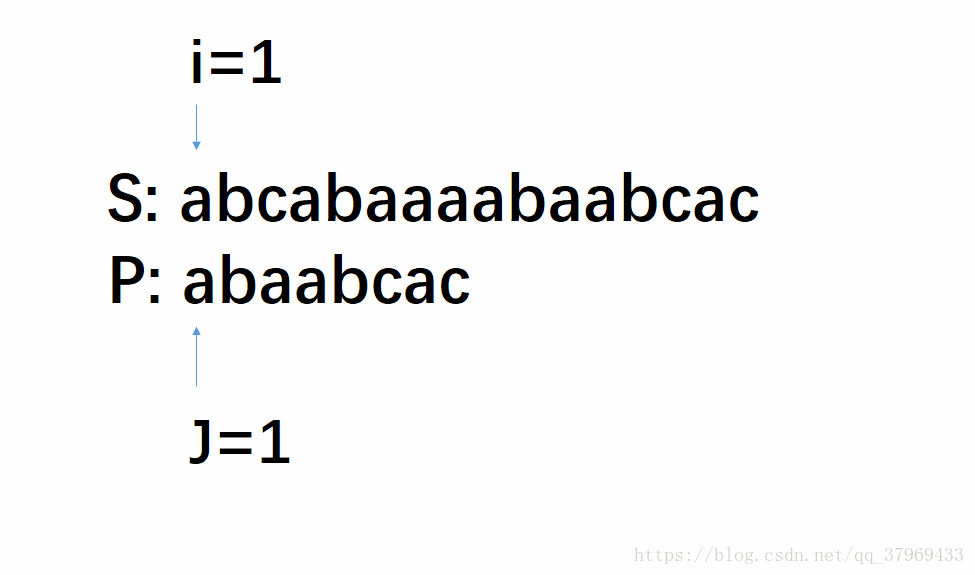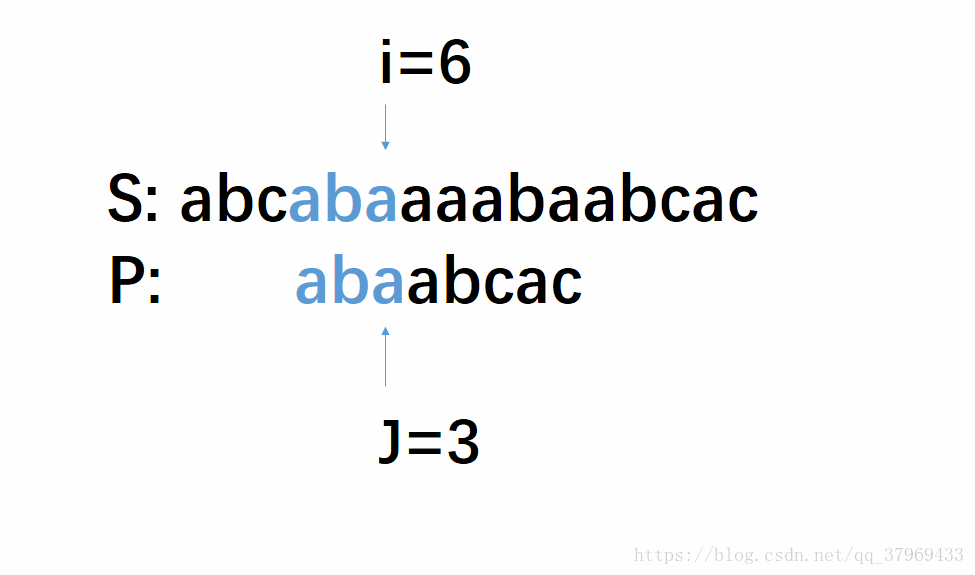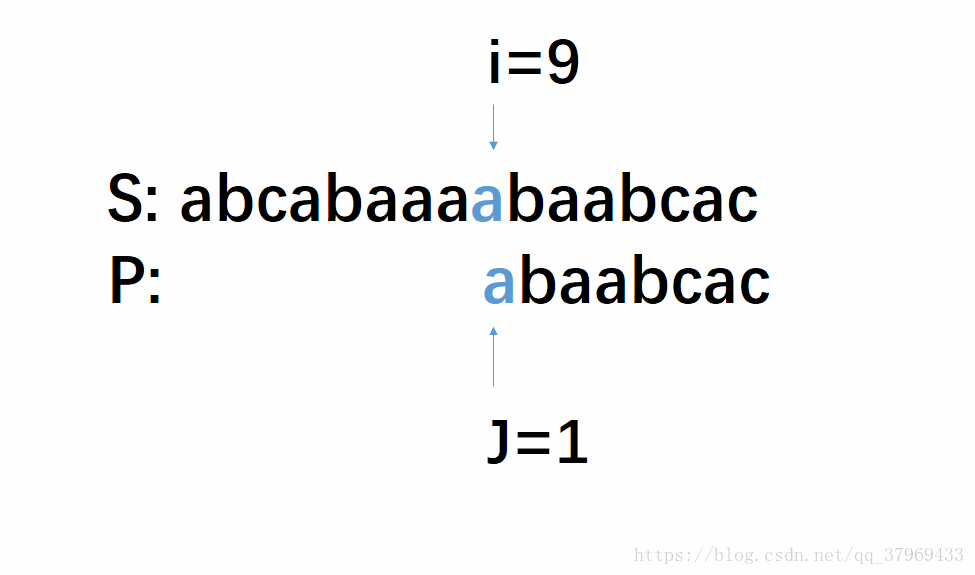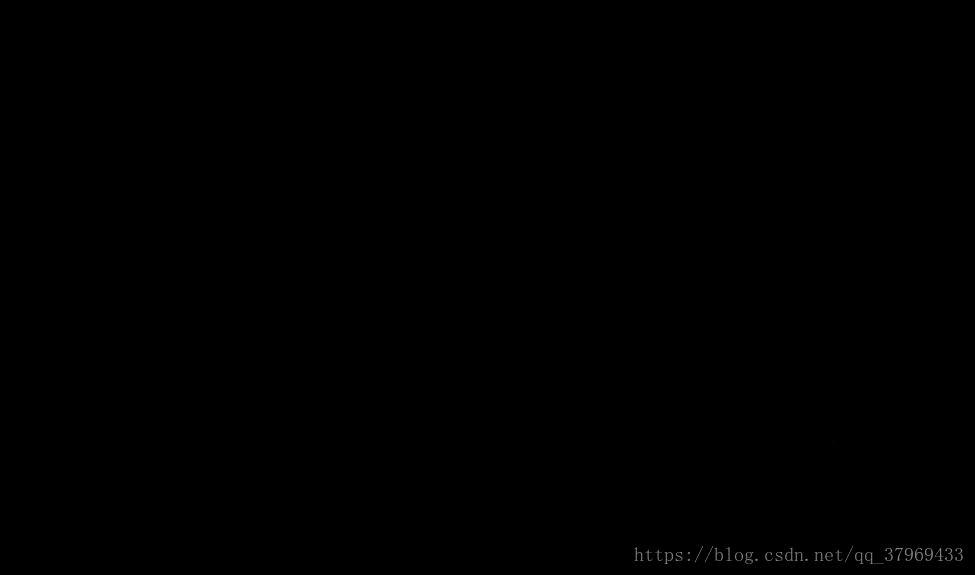
这个模拟过程即KMP算法,若没有看明白,继续往下看相应的解释,理解需要把P多移几位,然后回头再看一遍这个图就很明了了。
相比朴素算法:
朴素算法: 每次失配,S串的索引i定位的本次尝试匹配的第一个字符的后一个。P串的索引j定位到1;T(n)=O(n*m)。
KMP算法: 每次失配,S串的索引i不动,P串的索引j定位到某个数。T(n)=O(n+m),时间效率明显提高。
而这“定位到某个数”,这个数就是接下来引入的next值。
KMP算法用到了next数组,然后利用next数组的值来提高匹配速度,我首先讲一下next数组怎么求,之后再讲匹配方式。
next数组详解
首先是理解KMP算法的第一个难关是next数组每个值的确定,这个问题困恼我很长时间,尤其是对照着代码一行一行分析,很容易把自己绕进去。
定义一串字符串
ptr = "ababaaababaa";
next[i](i从1开始算)代表着,除去第i个数,在一个字符串里面从第一个数到第(i-1)字符串前缀与后缀最长重复的个数。
什么是前缀?
在“aba”中,前缀就是“ab”,除去最后一个字符的剩余字符串。
同理可以理解后缀。除去第一个字符的后面全部的字符串。
在“aba”中,前缀是“ab”,后缀是“ba”,那么两者最长的子串就是“a”;
在“ababa”中,前缀是“abab”,后缀是“baba”,二者最长重复子串是“aba”;
在“abcabcdabc”中,前缀是“abcabcdab”,后缀是“bcabcdabc”,二者最长重复的子串是“abc”;
这里有一点要注意,前缀必须要从头开始算,后缀要从最后一个数开始算,中间截一段相同字符串是不行的。
这里我们定义next[1] = 0 , next[2] = 1;
再分析ptr字符串,ptr = "ababaaababaa";
next[1] = 0 ,事先定义好的
next[2] = 1 ,事先定义好的
next[3] = 1 ,最长重复的子串“”;1代表没有重复,2代表有一个字符重复。
next[4] = 2 ,最长重复的子串“a”;追偿的长度加1,即为2.
next[5] = 3 ,以下都跟之前的一样,这种方法是最长的长度再加上一就可以了。
next[6] = 4
next[7] = 2
next[8] = 2
next[9] = 3
next[10] = 4
next[11] = 5
next[12] = 6
以上是next数组的详细解释。next数组求值 是比较麻烦的,剩下的匹配方式就很简单了。
next数组用于子串身上,根据上面的原理,我们能够推出子串a=“aab”的next数组的值分别为0,1,2。
首先开始计算主串与子串的字符,设置主串用i来表示,子串用j来表示,如果ptr[i]与a[i]相等,那么i与j就都加1:

prt[1]与a[1]相等,i++,j++:
用代码实现就是
if( j==0 || ptr[i]==a[j])
{
++i;
++j;
}

ptr[2]与a[2]不相等
此时ptr[2]!=a[2],那么令j = next[j],此时j=2,那么next[j] = next[2] = 1.那么此时j就等于1.这一段判断用代码解释的话就是:
if( ptr[i]!=a[j])
{
j = next[j];
}
加上上面的代码进行组合:
在对两个数组进行比对时,各自的i,j取值代码:
while( i<ptr.length && j< a.length)
{
if( j==0 || ptr[i]==a[i] )
{
++i;
++j;
next[i] = j;
}
else
{
j = next[j];
}
}
此时将a[j]置于j此时所处的位置,即a[1]放到j=2处,因为在j=2时出现不匹配的情况。

此时再次计算是否匹配,可以看出来a[1]!=ptr[2],那么j = next[j],即此时j = next[1] = 0;
根据上面的代码,当j=0时,执行++i;++j;
此时就变为:
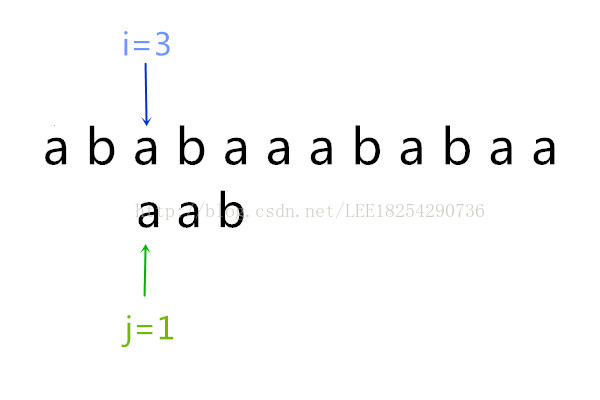
此时ptr[3] = a[1],继续向下走,下一个又不相等了,然后“aab”向后挪一位,这里不再赘述了,主要的思想已经讲明白了。到最后一直到i = 8,j=3时匹配成功,KMP算法结束。整个过程就结束了。
Next完整代码:
int GetNext(char ch[],int cLen,int next[]){//cLen为串ch的长度
next[1] = 0;
int i = 1,j = 0;
while(i<=cLen){
if(j==0||ch[i]==ch[j]) next[++i] = ++j;
else j = next[j];
}
}
一、问题描述
给定一个主串S及一个模式串P,判断模式串是否为主串的子串;若是,返回匹配的第一个元素的位置(序号从1开始),否则返回0;如S=“abcd”,P=“bcd”,则返回2;S=“abcd”,P=“acb”,返回0。
二、朴素算法
最简单的方法及一次遍历S与P。以S=“abcabaaaabaaacac”,P="abaabcac"为例,一张动图模拟朴素算法:
这个算法简单,不多说,附上代码
#include<stdio.h>
int Index_1(char s[],int sLen,char p[],int pLen){//s为主串,sLen为主串元素个数,p为模式串,pLen为模式串的个数
if(sLen<pLen)return 0;
int i = 1,j = 1;
while(i<=sLen && j<=pLen){
if(s[i]==p[j]){i++;j++;}
else{
i = i-j+2;
j = 1;
}
}
if(j>pLen) return i-pLen;
return 0;
}
void main(){
char s[]={' ','a','b','c','a','b','a','a','a','a','b','a','a','b','c','a','c'};//从序号1开始存
char p[]={' ','a','b','a','a','b','c','a','c'};
int sLen = sizeof(s)/sizeof(char)-1;
int pLen = sizeof(p)/sizeof(char)-1;
printf("%d",Index_1(s,sLen,p,pLen));
}
三、改进的算法——KMP算法
朴素算法理解简单,但两个串都有依次遍历,时间复杂度为O(n*m),效率不高。由此有了KMP算法。
一般的,在一次匹配中,我们是不知道主串的内容的,而模式串是我们自己定义的。
朴素算法中,P的第j位失配,默认的把P串后移一位。
但在前一轮的比较中,我们已经知道了P的前(j-1)位与S中间对应的某(j-1)个元素已经匹配成功了。这就意味着,在一轮的尝试匹配中,我们get到了主串的部分内容,我们能否利用这些内容,让P多移几位(我认为这就是KMP算法最根本的东西),减少遍历的趟数呢?答案是肯定的。再看下面改进后的动图:
这个模拟过程即KMP算法,若没有看明白,继续往下看相应的解释,理解需要把P多移几位,然后回头再看一遍这个图就很明了了。
相比朴素算法:
朴素算法: 每次失配,S串的索引i定位的本次尝试匹配的第一个字符的后一个。P串的索引j定位到1;T(n)=O(n*m)。
KMP算法: 每次失配,S串的索引i不动,P串的索引j定位到某个数。T(n)=O(n+m),时间效率明显提高。
而这“定位到某个数”,这个数就是接下来引入的next值。
KMP算法用到了next数组,然后利用next数组的值来提高匹配速度,我首先讲一下next数组怎么求,之后再讲匹配方式。
next数组详解
首先是理解KMP算法的第一个难关是next数组每个值的确定,这个问题困恼我很长时间,尤其是对照着代码一行一行分析,很容易把自己绕进去。
定义一串字符串
ptr = "ababaaababaa";
next[i](i从1开始算)代表着,除去第i个数,在一个字符串里面从第一个数到第(i-1)字符串前缀与后缀最长重复的个数。
什么是前缀?
在“aba”中,前缀就是“ab”,除去最后一个字符的剩余字符串。
同理可以理解后缀。除去第一个字符的后面全部的字符串。
在“aba”中,前缀是“ab”,后缀是“ba”,那么两者最长的子串就是“a”;
在“ababa”中,前缀是“abab”,后缀是“baba”,二者最长重复子串是“aba”;
在“abcabcdabc”中,前缀是“abcabcdab”,后缀是“bcabcdabc”,二者最长重复的子串是“abc”;
这里有一点要注意,前缀必须要从头开始算,后缀要从最后一个数开始算,中间截一段相同字符串是不行的。
这里我们定义next[1] = 0 , next[2] = 1;
再分析ptr字符串,ptr = "ababaaababaa";
next[1] = 0 ,事先定义好的
next[2] = 1 ,事先定义好的
next[3] = 1 ,最长重复的子串“”;1代表没有重复,2代表有一个字符重复。
next[4] = 2 ,最长重复的子串“a”;追偿的长度加1,即为2.
next[5] = 3 ,以下都跟之前的一样,这种方法是最长的长度再加上一就可以了。
next[6] = 4
next[7] = 2
next[8] = 2
next[9] = 3
next[10] = 4
next[11] = 5
next[12] = 6
以上是next数组的详细解释。next数组求值 是比较麻烦的,剩下的匹配方式就很简单了。
next数组用于子串身上,根据上面的原理,我们能够推出子串a=“aab”的next数组的值分别为0,1,2。
首先开始计算主串与子串的字符,设置主串用i来表示,子串用j来表示,如果ptr[i]与a[i]相等,那么i与j就都加1:
prt[1]与a[1]相等,i++,j++:
用代码实现就是
if( j==0 || ptr[i]==a[j])
{
++i;
++j;
}
ptr[2]与a[2]不相等
此时ptr[2]!=a[2],那么令j = next[j],此时j=2,那么next[j] = next[2] = 1.那么此时j就等于1.这一段判断用代码解释的话就是:
if( ptr[i]!=a[j])
{
j = next[j];
}
加上上面的代码进行组合:
在对两个数组进行比对时,各自的i,j取值代码:
while( i<ptr.length && j< a.length)
{
if( j==0 || ptr[i]==a[i] )
{
++i;
++j;
next[i] = j;
}
else
{
j = next[j];
}
}
此时将a[j]置于j此时所处的位置,即a[1]放到j=2处,因为在j=2时出现不匹配的情况。
此时再次计算是否匹配,可以看出来a[1]!=ptr[2],那么j = next[j],即此时j = next[1] = 0;
根据上面的代码,当j=0时,执行++i;++j;
此时就变为:
此时ptr[3] = a[1],继续向下走,下一个又不相等了,然后“aab”向后挪一位,这里不再赘述了,主要的思想已经讲明白了。到最后一直到i = 8,j=3时匹配成功,KMP算法结束。整个过程就结束了。
Next完整代码:
int GetNext(char ch[],int cLen,int next[]){//cLen为串ch的长度
next[1] = 0;
int i = 1,j = 0;
while(i<=cLen){
if(j==0||ch[i]==ch[j]) next[++i] = ++j;
else j = next[j];
}
}
- 上一篇:什么是时间复杂度?时间复杂度算法原理
- 下一篇:大数据商品推荐算法原理
精品好课

HTML5基础入门视频教程,教学思路清晰,简单易学必会。适合人群:创业者,只要会打字,对互联网编程感兴趣都可以学。课程概述:该课程主要讲解HTML(学习HTML5的必备基础语言)、CSS3、Javascript(学习...
React是前端最火的框架之一,就业薪资很高,本课程教您如何快速学会React并应用到实战,对正在工作当中或打算学习React高薪就业的你来说,那么这门课程便是你手中的葵花宝典。
2021年最新Vue2+Vue3+ES6+TypeScript和uni-app开发微信小程序从入门到实战视频教程,本课程教你如何快速学会VUE和uni-app并应用到实战,教你如何解决内存泄漏,常用UI库的使用,自己...
适用人群1、有html基础2、有css基础3、有javascript基础课程概述手把手教你如何开发属于自己的HTML5视频播放器,利用mp4转成m3u8格式的视频,并在移动端和PC端进行播放支持m3u8直播格式,兼容...
jquery视频教程从入门到精通,课程主要包含:jquery选择器、jquery事件、jquery文档操作、动画、Ajax、jquery插件的制作、jquery下拉无限加载插件的制作等等......
React是目前最火的前端框架,就业薪资很高,本课程教您如何快速学会React并应用到实战,教你如何解决内存泄漏,常用UI库的使用,自己封装组件,正式上线白屏问题,性能优化等。对正在工作当中或打算学习React高薪就...
React和VUE是目前最火的前端框架,就业薪资很高,本课程教您如何快速学会React和VUE并应用到实战,教你如何解决内存泄漏,常用库的使用,自己封装组件,正式上线白屏问题,性能优化等。对正在工作当中或打算学习Re...
VUE是目前最火的前端框架之一,就业薪资很高,本课程教您如何快速学会VUE+ES6并应用到实战,教你如何解决内存泄漏,常用UI库的使用,自己封装组件,正式上线白屏问题,性能优化等。对正在工作当中或打算学习VUE高薪就...