js正则表达式知识大全
日期:2020-05-13
来源:程序思维浏览:2104次
今天给大家介绍一下javascript正则表达式知识大全,看看你都会吗?

1.转义字符
*转义字符 *
\r叫做行结束符,
\n叫做换行符,
\t叫做制表符
var str = "abcde\"d\"f";
console.log(str);//abcde"d"f
多行字符串
第一种:
var test = "\
<div></div>\
<span><span>\
";
第二种方式:利用换行符\n
第三种:加号连接
var test = "
<div></div>+
<span><span>+
";

例如输入邮箱是符合格式要求,如何输入前两位相同后两位相同等
1.直接量(推荐)
var reg = /abc/;//我匹配的规则叫abc,字符串是否有abc连着的字符串
var reg = /abc/i;
修饰符:
参数是一个可选的字符串,包含属性 “g”、“i” 和 “m”,分别用于指定全局匹配、区分大小写的匹配和多行匹配。
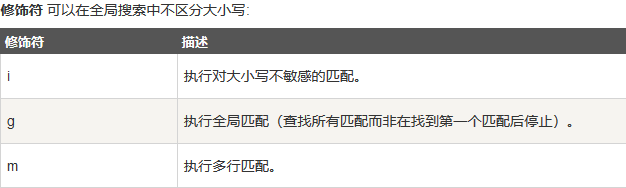
m (首先要匹配的字符串要是多行的,匹配开头和结尾)
var reg = /^a/gm;
var str = "abcde\na";
console.log(str.match(reg));// ["a", "a"]
2.构造方法
var reg = new RegExp("abc");
var reg = new RegExp("abc","i");
var reg1 = new RegExp(reg);
这样创建出来的reg和reg1虽然是一样的。但是它们确实是两个不同的对象。
var reg2 = RegExp(reg)
没有了new的时候,它们两个就是完全一样的对象
3.正则表达式规则

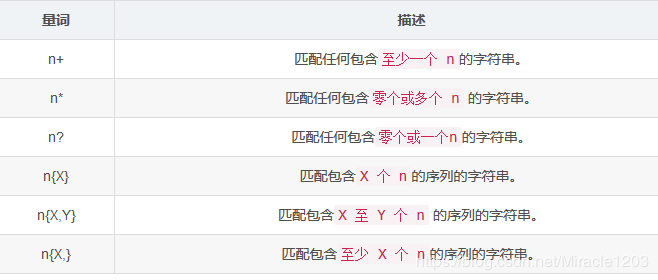
n+ : {1,} 个数是一个到无穷个
n* : {0,} 个数是0个到无穷个
n? : {0,1} 个数是0个或一个
var reg = /\w+/g/ // \w === [0-9A-z]
var str = "abc";
console.log(str.match(reg));//["abc"]
var reg = /\d+/g //\d === [0-9]
var str = "abc";
console.log(str.match(reg));//null
var reg = /\d*/g
var str = "abc";
console.log(str.match(reg));//["", "", "", ""]按照光标位置找0个到无穷个数字,因为是贪婪匹配,所以就要尽可能的匹配的数量要多,每一个光标处都为空,逻辑上为空字符串也被匹配到了。
var reg = /\d*/g
var str = "abc4";
console.log(str.match(reg));//["", "", "", "4", ""]因为是贪婪匹配,用了*就是0个到多个那么就不仅仅是只匹配数字4就完了,它还要根据光标位置找逻辑上的空字符串
var reg = /\w?/g;
var str = "aaaaaaa";
console.log(str.match(reg));// ["a", "a", "a", "a", "a", "a", "a", ""]按照光标位置找0个或者1个字母或者数字,最后一光标位置就是在最后一个a的后面在逻辑上的为空
n{x} {x} 个数就是x个
n{x,y} {x,y} 个数就是x到y个
n{x,} {x,} 个数就是x到无穷个
var reg = /\w{3}/g;
var str = "aaaaaaa";
console.log(str.match(reg));// ["aaa", "aaa"]
var reg = /\w{3,5}/g;
var str = "aaaaaaaaaaaaaa";
console.log(str.match(reg));// ["aaaaa", "aaaaa", "aaaa"]贪婪匹配先赶着长的来,5个的先来,然后就剩下4个也匹配到了
var reg = /\w{1,}/g;
var str = "aaaaaaaaaaaaaa";
console.log(str.match(reg));//["aaaaaaaaaaaaaa"]
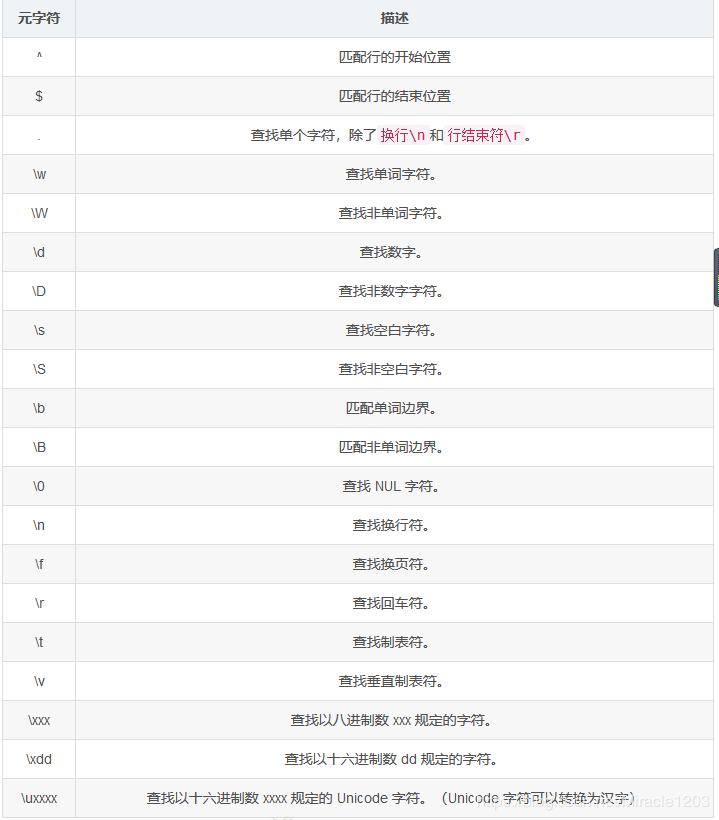
. === [^\r\n]
\w === [0-9A-z]
\W === [^\w]
\d === [0-9]
\D === [^\d]
\s === [\t\n\r\f\v]
\S === [^\s]
\b === 单词边界
\B === 非单词边界
4.正则表达式方法
test()方法
正则表达式常用方法test(),它接受一个字符串参数。在模式与该参数匹配的情况下返回true,否则返回false。
用法:正则.test(字符串)
例1:判断是否是数字
var str = '374829348791';
var re = /\D/; // \D代表非数字
if( re.test(str) ){ // 返回true,代表在字符串中找到了非数字。
alert('不全是数字');
}else{
alert('全是数字');
}
search()方法
在字符串搜索符合正则的内容,搜索到就返回出现的位置(从0开始,如果匹配的不只是一个字母,那只会返回第一个字母的位置)
如果搜索失败就返回 -1
用法:字符串.search(正则)
例子:在字符串中找字母b,且不区分大小写
var str = 'abcdef';
var re = /B/i;
//var re = new RegExp('B','i'); 也可以这样写
alert( str.search(re) ); // 1
match方法
语法:
stringObject.match(searchvalue)
stringObject.match(regexp)
searchvalue:必需。规定要检索的字符串值。
regexp:必需。规定要匹配的模式的 RegExp 对象。如果该参数不是 RegExp 对象,则需要首先把它传递给 RegExp 构造函数,将其转换为 RegExp 对象。
如果 regexp 没有标志 g,那么 match() 方法就只能在 stringObject
中执行一次匹配。如果没有找到任何匹配的文本, match() 将返回 null。否则,它将返回一个数组。
例如:
"186a619b28".match(/\d+/g); // ["186","619","28"]
如果上面的匹配不是全局匹配,那么得到的结果如下:
`["186", index: 0, input: "186a619b28"]`
replace方法
replace 本身是JavaScript字符串对象的一个方法,它允许接收两个参数:
replace([RegExp|String],[String|Function])
第1个参数可以是一个普通的字符串或是一个正则表达式.
第2个参数可以是一个普通的字符串或是一个回调函数.
如果第2个参数是回调函数,每匹配到一个结果就回调一次,每次回调都会传递以下参数:
result: 本次匹配到的结果
1,…9: 正则表达式中有几个(),就会传递几个参数,1 9分别代表本次匹配中每个()提取的结果,最多9个
offset:记录本次匹配的开始位置
source:接受匹配的原始字符串
以下是replace和JS正则搭配使用的几个常见经典案例:
$1$2…表示第几个子表达式
(1)实现字符串的trim函数,去除字符串两边的空格
String.prototype.trim = function(){
//方式一:将匹配到的每一个结果都用""替换
return this.replace(/(^\s+)|(\s+$)/g,function(){
return "";
});
//方式二:和方式一的原理相同
return this.replace(/(^\s+)|(\s+$)/g,'');
};
^s+ 表示以空格开头的连续空白字符,s+$ 表示以空格结尾的连续空白字符,加上() 就是将匹配到的结果提取出来,由于是 | 的关系,因此这个表达式最多会match到两个结果集,然后执行两次替换:
String.prototype.trim = function(){
/**
* @param rs:匹配结果
* @param $1:第1个()提取结果
* @param $2:第2个()提取结果
* @param offset:匹配开始位置
* @param source:原始字符串
*/
this.replace(/(^\s+)|(\s+$)/g,function(rs,$1,$2,offset,source){
//arguments中的每个元素对应一个参数
console.log(arguments);
});
};
" abcd ".trim();
输出结果:
[" ", " ", undefined, 0, " abcd "] //第1次匹配结果
[" ", undefined, " ", 5, " abcd "] //第2次匹配结果
(2)提取浏览器url中的参数名和参数值,生成一个key/value的对象
function getUrlParamObj(){
var obj = {};
//获取url的参数部分
var params = window.location.search.substr(1);
//[^&=]+ 表示不含&或=的连续字符,加上()就是提取对应字符串
params.replace(/([^&=]+)=([^&=]*)/gi,function(rs,$1,$2){
obj[$1] = $2;
});
return obj;
}
/([&=]+)=([&=]*)/gi 每次匹配到的都是一个完整key/value,形如 xxxx=xxx, 每当匹配到一个这样的结果时就执行回调,并传递匹配到的key和value,对应到$1和$2
(3)在字符串指定位置插入新字符串
String.prototype.insetAt = function(str,offset){
//使用RegExp()构造函数创建正则表达式
var regx = new RegExp("(.{"+offset+"})");
return this.replace(regx,"$1"+str);
};
"abcd".insetAt('xyz',2); //在b和c之间插入xyz
//结果 "abxyzcd"
当offset=2时,正则表达式为:(^.{2}) .表示除\n之外的任意字符,后面加{2} 就是匹配以数字或字母组成的前两个连续字符,加()就会将匹配到的结果提取出来,然后通过replace将匹配到的结果替换为新的字符串,形如:结果=结果+str
(4) 将手机号12988886666转化成129 8888 6666
function telFormat(tel){
tel = String(tel);
//方式一
return tel.replace(/(\d{3})(\d{4})(\d{4})/,function (rs,$1,$2,$3){
return $1+" "+$2+" "+$3
});
//方式二
return tel.replace(/(\d{3})(\d{4})(\d{4})/,"$1 $2 $3");
}
(\d{3}\d{4}\d{4}) 可以匹配完整的手机号,并分别提取前3位、4-7位和8-11位,"$1 $2 $3" 是在三个结果集中间加空格组成新的字符串,然后替换完整的手机号。
替换 XXYY---->YYXX
var str = "aabb";
var reg = /(\w)\1(\w)\2/g
console.log(str.replace(reg, "$2$2$1$1"));//bbaa
var str = "aabb";
var reg = /(\w)\1(\w)\2/g
console.log(str.replace(reg, function($, $1, $2) {//replace的第二个参数也可以传进去一个函数,但是如果要用子表达式,那么就必须先传$,然后再传要用的子表达式。
return $2 + $2 + $1 + $1;//子表达式用$取的时候要用加号把它们连接起来
}));//bbaa
替换the-first-name-------->theFirstName
var reg = /-(\w)/g; //因为要操作f和n让它们变成大写,所以要用子表达式的方式传递
var str = "the-first-name";
console.log(str.replace(reg, function($, $1){
return $1.toUpperCase();
}))
3、字符串去重
var str = "aaaaaaaaaaaaaaaaabbbbbbbbbbbbbbbbbbbbbccccccccccccc";
var reg = /(\w)\1*/g;
console.log(str.replace(reg, "$1"));// abc
4、实现从后往前每3个0打个小数点
var str = "10000000000";
var reg = /(?=(\B)(\d{3})+$)/g
//从末尾开始,然后找3个数字连在一起的(\d{3})+$,然后用?=前面为空就表示正向预查空的地方,
//最后添加(\B)是因为如果0的个数为偶数(假设100000000000),那么就会出现.100.000.000.000这样的情况,所以就要加上非单词边界
console.log(str.replace(reg, "."));//10.000.000.000
exec()方法
该方法是专门为捕获组而设计的,其接受一个参数,即要应用模式的字符串,然后返回包含第一个匹配项信息的数组;
在没有匹配项的情况下返回null。返回的数组虽然是Array的实例,但是包含两个额外的属性:index和input
其中index表示匹配项在字符串中的位置,而input表示应用字符串表达式的字符串。
var text = "mom and dad and baby";
var pattern = /mom( and dad( and baby)?)?/gi;
var matches = pattern.exec(text);
console.log(matches.index); //0
console.log(matches.input); //mom and dad and baby
console.log(matches[0]); //mom and dad and baby
console.log(matches[1]); //and dad and baby
console.log(matches[2]); //and baby
对于exec()方法而言,即使在模式中设置了全局标志g,它每次也只是返回一个匹配项。
在不设置全局标志的情况下,在同一个字符串上多次调用exec()方法将始终返回第一个匹配项的信息。
而在设置全局标志的情况下,每次调用exec()则都会在字符串中继续查找新匹配项,如下例子:
var text = "cat, bat, sat, fat";
var pattern1 = /.at/;
var matches = pattern1.exec(text);
console.log(matches.index); //0
console.log(matches[0]); //cat
console.log(pattern1.lastIndex); //0
matches = pattern1.exec(text);
console.log(matches.index); //0
console.log(matches[0]); //cat
console.log(pattern1.lastIndex); //0
var pattern2 = /.at/g;
var matches = pattern2.exec(text);
console.log(matches.index); //0
console.log(matches[0]); //cat
console.log(pattern2.lastIndex); //3
var matches = pattern2.exec(text);
console.log(matches.index); //5
console.log(matches[0]); //bat
console.log(pattern2.lastIndex); //8
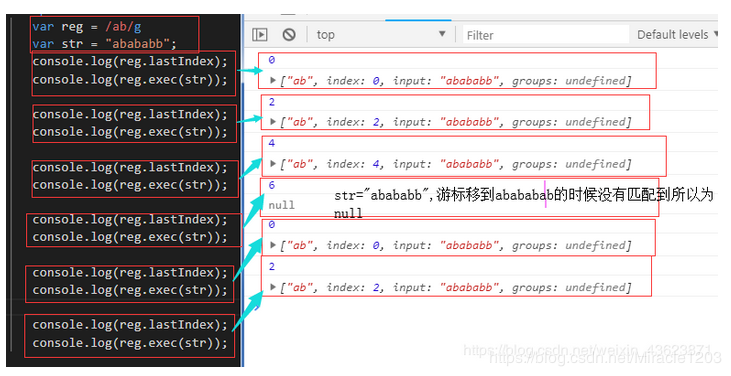
IE的JavaScript实现lastIndex属性上存在偏差,即使在非全局模式下,lastIndex属性每次也都在变化。
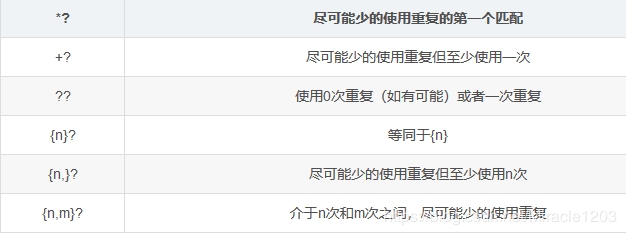
5.贪婪匹配与非贪婪匹配
贪婪匹配:
贪婪匹配就是仅仅使用单个限定符:*,+,?,n{X},n{X,},n{X,Y}的匹配。
正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配。
非贪婪匹配(懒惰匹配):
非贪婪匹配就是在限定符*,+,?,n{X},n{X,},n{X,Y}之后再添加一个字符?,则尽可能少的重复字符“?”之前的限定符号的重复次数
非贪婪匹配就是匹配到结果就好,就少的匹配字符。
默认是贪婪模式;
在量词后面直接加上一个问号?就是非贪婪模式。
var str = "aaaaaa";
var reg = /a{1,3}?/g;
console.log(str.match(reg));// ["a", "a", "a", "a", "a", "a"]
var str = "aaaaaa";
var reg = /a??/g;
console.log(str.match(reg));// ["", "", "", "", "", "", ""]
var str = "aaaaaa";
var reg = /a*?/g;
console.log(str.match(reg));// ["", "", "", "", "", "", ""]
var str = "aaa aaa";
var reg = / /g;
console.log(str.match(reg));// [" "]
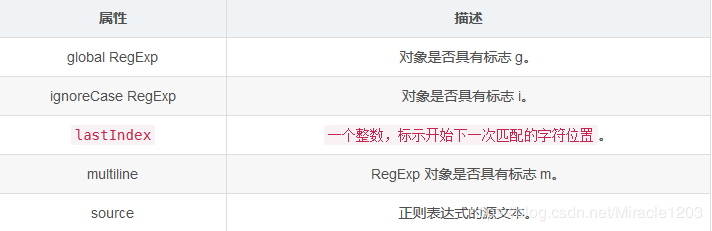
6.正则表达式对象属性
multiline 是一个只读的布尔值,看这个正则表达式是否带有修饰符m。
修饰符m,用以在多行模式中执行匹配,需要配合^ 和 $ 使用,使用^ 和 $ 除了匹配整个字符串的开始和结尾之外,还能匹配每行的开始和结尾。
主要用来匹配多行模式
var str="java\nJavaScript";
str.match(/^JavaScript/); //返回null
var str="java\nJavaScript";
str.match(/^JavaScript/m); //匹配到一个JavaScript
var reg=/JavaScript/;
reg.multiline; //返回false
var reg=/JavaScript/m;
reg.multiline; //返回true
lastIndex
lastIndex:是一个可读/写的整数,如果匹配模式中带有g修饰符,这个属性存储在整个字符串中下一次检索的开始位置,这个属性会被exec( ) 和 test( ) 方法用到。
注:此属性需要单独说明,在exec和test方法下会用到并且改变正则对象的该属性值。
source
source:是一个只读的字符串,包含正则表达式的文本。
var reg = /Abc/;
reg.source; //返回 Abc
global
global:是一个只读的布尔值,看这个正则表达式是否带有修饰符g。
修饰符g,是全局匹配的意思,检索字符串中所有的匹配。
var str = "JavaScript";
str.match(/JavaScript/); //只能匹配一个JavaScript
var str = "JavaScript JavaScript";
str.match(/JavaScript/g); //能匹配两个JavaScript
var reg = /JavaScript/;
reg.global; //返回 false
var reg = /JavaScript/g;
reg.global; //返回 true
ignoreCase
ignoreCase:是一个只读的布尔值,看这个正则表达式是否带有修饰符i。
修饰符i,说明模式匹配是不区分大小写的。
var reg = /JavaScript/;
reg.ignoreCase; //返回 false
var reg = /JavaScript/i;
reg.ignoreCase; //返回 true
var reg = /JavaScript/;
reg.test("javascript"); //返回 false
var reg = /JavaScript/i;
reg.test("javascript"); //返回 true
支持正则表达式的 String 对象的方法
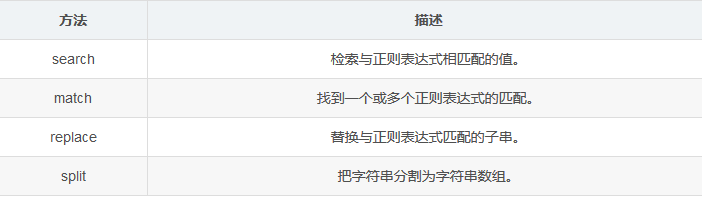
字符串replace的局限性就在于这,这就需要与正则表达式相结合完成替换
var str = "aa";
console.log(str.replace("a","b"));//ba
var reg = /a/ //没有g它也是匹配到了一个就停止了。
var str = "aa";
console.log(str.replace(reg,"b"));//ba
var reg = /a/g
var str = "aa";
console.log(str.replace(reg,"b"));//bb
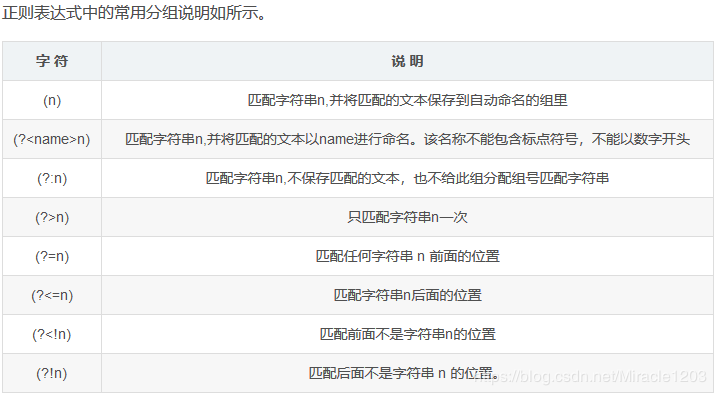
7.分组和反向引用一个子表达式里面的内容
分组又称为子表达式,首先一个子表达式是用()表示的。
当一个正则表达式被分组之后,每一个组被自动赋予一个组号,该组号可以代表该组的 表达式。
1.匹配XX的片段
var str = "aaaa";
var reg = /(a)\1/g //\1就表示反向引用第一个子表达式(a)的内容
console.log(str.match(reg));//["aa", "aa"]
2.匹配XXXX的片段
var str = "aaaabbbb"; //\1\1\1就表示三次反向引用第一个子表达式(\w)的内容
var reg = /(\w)\1\1\1/g
console.log(str.match(reg));// ["aaaa", "bbbb"]
3.匹配XXXX的片段
var str = "aaaabbbb";
var reg = /(\w)\1\1\1/ //没有g全局搜索就会匹配到了之后就会停止
console.log(str.match(reg));//["aaaa", "a", index: 0, input: "aaaabbbb", groups: undefined]
console.log(reg.exec(str));//["aaaa", "a", index: 0, input: "aaaabbbb", groups: undefined]
var str = "aaaabbbb";
var reg = /(\w)\1\1\1/g
console.log(str.match(reg)); //["aaaa", "bbbb"]
console.log(reg.exec(str));//["aaaa", "a", index: 0, input: "aaaabbbb", groups: undefined]
4.匹配XXYY的形式
var str = "aabbbbcdfsf";
var reg = /(\w)\1(\w)\2/g //\1反向引用第一个子表达式,那么\2就表示反向引用第二个子表达式,还可以有\3,\4,\5........表示反向引用第3,4,5个子表达式的内容
console.log(str.match(reg));// ["aabb"]
var str = "aabbbbcdkkoo";
var reg = /(\w)\1(\w)\2/g
console.log(str.match(reg));// ["aabb", "kkoo"]
var str = "aabbbbcdfsf";
var reg = /(\w)\1(\w)\2/ //没有全局搜索用str.match()就会出现返回子表达式的内容还有一些其他的信息。
console.log(str.match(reg));// ["aabb", "a", "b", index: 0, input: "aabbbbcdfsf", groups: undefined]
没有全局搜索g用str.match()就会出现返回子表达式的内容还有一些其他的信息。
无论有没有g用reg.exec()都会出现返回子表达式的内容还有一些其他的信息,因为这是exec()方法 的特性。
分组不但可以使用数字作为组号,而且还可以使用自定义名称作为组号。
1.以下两个正则表达式都是将分组后的子表达式w+命名为“word”.
(?\w+)
(? ‘word’ \w+)
2.因此,正则表达式\b(\w+)\b\s+\1\b和以下正则表达式等价,它们都匹配重复出现的单词。
\b(?\W+)\b\s+\k\b
3.以下正则表达式和正则表达式\b\w*(\w+)\1\b等价,它也是匹配以两个重复字符结尾的单词。
\b\w* (?\w+)\k\b
4.分组子表达式(?)将元字符括在其中,并强制正则表达式引擎记住该子表达式匹配,同时使用“name”对该匹配进行命名。
反向引用\k使引擎对当前字符和以名称“name”存储的先前匹配字符进行比较,从而匹配具有重复字符的字符串。
8.优先级顺序

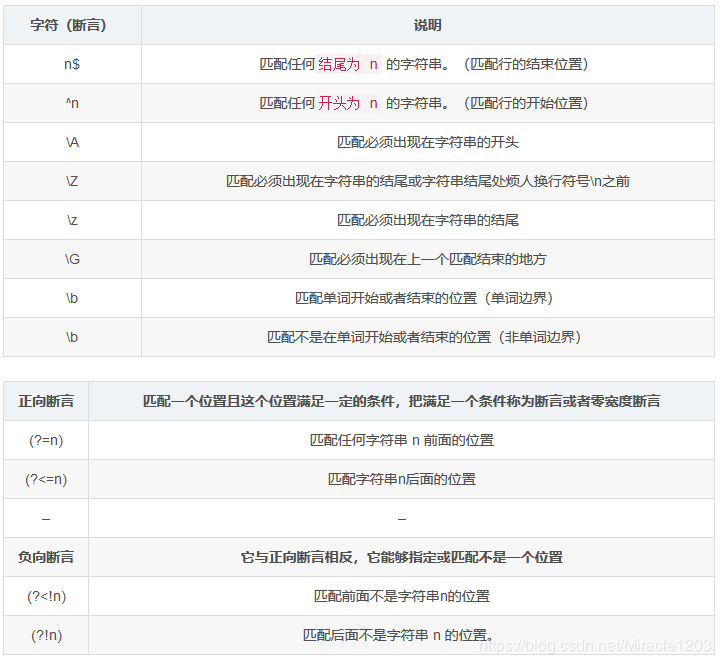
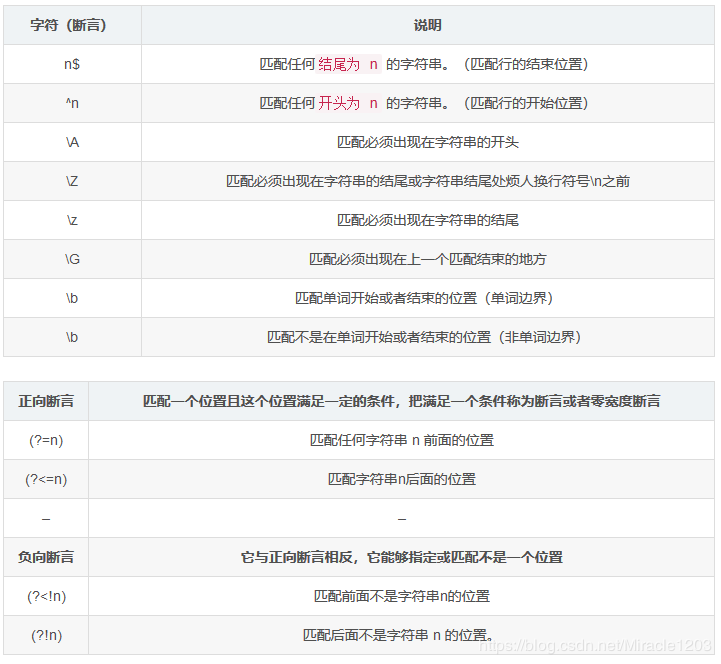
9.断言
零宽断言
匹配宽度为零,满足一定的条件/断言。
零宽断言用于查找在某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们像\b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言),因此它们也被称为零宽断言。
断言用来声明一个应该为真的事实。正则表达式中只有当断言为真时才会继续进行匹配
先行断言(零宽度正预测先行断言)
表达式:(?=表达式)
表示匹配表达式前面的位置
先行断言的执行步骤是这样的先从要匹配的字符串中的最右端找到第一个ing(也就是先行断言中的表达式)然后 再匹配其前面的表达式,若无法匹配则继续查找第二个ing 再匹配第二个 ing前面的字符串,若能匹配 则匹配
.*(?=d) 可c以匹配abcdefghi 中的abc
后发断言(零宽度正回顾后发断言)
表达式: (?<=表达式)
表示匹配表达式后面的位置
后发断言跟先行断言恰恰相反 它的执行步骤是这样的:
先从要匹配的字符串中的最左端找到第一个abc(也就是先行断言中的表达式)然后 再匹配其后面的表达式,
若无法匹配则继续查找第二个abc 再匹配第二个abc后面的字符串,若能匹配 则匹配
例如(?<=abc).* 可以匹配abcdefg中的defg
负向断言
负向零宽先行断言 :(?!表达式)
负向零宽后发断言:(?<!表达式)
负向零宽断言 (?!表达式) 也是匹配一个零宽度的位置,不过这个位置的“断言”取表达式的反值,
例如 (?!表达式) 表示 表达式 前面的位置,如果 表达式 不成立 ,匹配这个位置;
如果 表达式 成立,则不匹配:同样,负向零宽断言也有“先行”和“后发”两种,负向零宽后发断言为 (?<!表达式)
1.转义字符
*转义字符 *
\r叫做行结束符,
\n叫做换行符,
\t叫做制表符
var str = "abcde\"d\"f";
console.log(str);//abcde"d"f
多行字符串
第一种:
var test = "\
<div></div>\
<span><span>\
";
第二种方式:利用换行符\n
第三种:加号连接
var test = "
<div></div>+
<span><span>+
";
例如输入邮箱是符合格式要求,如何输入前两位相同后两位相同等
1.直接量(推荐)
var reg = /abc/;//我匹配的规则叫abc,字符串是否有abc连着的字符串
var reg = /abc/i;
修饰符:
参数是一个可选的字符串,包含属性 “g”、“i” 和 “m”,分别用于指定全局匹配、区分大小写的匹配和多行匹配。
m (首先要匹配的字符串要是多行的,匹配开头和结尾)
var reg = /^a/gm;
var str = "abcde\na";
console.log(str.match(reg));// ["a", "a"]
2.构造方法
var reg = new RegExp("abc");
var reg = new RegExp("abc","i");
var reg1 = new RegExp(reg);
这样创建出来的reg和reg1虽然是一样的。但是它们确实是两个不同的对象。
var reg2 = RegExp(reg)
没有了new的时候,它们两个就是完全一样的对象
3.正则表达式规则
n+ : {1,} 个数是一个到无穷个
n* : {0,} 个数是0个到无穷个
n? : {0,1} 个数是0个或一个
var reg = /\w+/g/ // \w === [0-9A-z]
var str = "abc";
console.log(str.match(reg));//["abc"]
var reg = /\d+/g //\d === [0-9]
var str = "abc";
console.log(str.match(reg));//null
var reg = /\d*/g
var str = "abc";
console.log(str.match(reg));//["", "", "", ""]按照光标位置找0个到无穷个数字,因为是贪婪匹配,所以就要尽可能的匹配的数量要多,每一个光标处都为空,逻辑上为空字符串也被匹配到了。
var reg = /\d*/g
var str = "abc4";
console.log(str.match(reg));//["", "", "", "4", ""]因为是贪婪匹配,用了*就是0个到多个那么就不仅仅是只匹配数字4就完了,它还要根据光标位置找逻辑上的空字符串
var reg = /\w?/g;
var str = "aaaaaaa";
console.log(str.match(reg));// ["a", "a", "a", "a", "a", "a", "a", ""]按照光标位置找0个或者1个字母或者数字,最后一光标位置就是在最后一个a的后面在逻辑上的为空
n{x} {x} 个数就是x个
n{x,y} {x,y} 个数就是x到y个
n{x,} {x,} 个数就是x到无穷个
var reg = /\w{3}/g;
var str = "aaaaaaa";
console.log(str.match(reg));// ["aaa", "aaa"]
var reg = /\w{3,5}/g;
var str = "aaaaaaaaaaaaaa";
console.log(str.match(reg));// ["aaaaa", "aaaaa", "aaaa"]贪婪匹配先赶着长的来,5个的先来,然后就剩下4个也匹配到了
var reg = /\w{1,}/g;
var str = "aaaaaaaaaaaaaa";
console.log(str.match(reg));//["aaaaaaaaaaaaaa"]
. === [^\r\n]
\w === [0-9A-z]
\W === [^\w]
\d === [0-9]
\D === [^\d]
\s === [\t\n\r\f\v]
\S === [^\s]
\b === 单词边界
\B === 非单词边界
4.正则表达式方法
test()方法
正则表达式常用方法test(),它接受一个字符串参数。在模式与该参数匹配的情况下返回true,否则返回false。
用法:正则.test(字符串)
例1:判断是否是数字
var str = '374829348791';
var re = /\D/; // \D代表非数字
if( re.test(str) ){ // 返回true,代表在字符串中找到了非数字。
alert('不全是数字');
}else{
alert('全是数字');
}
search()方法
在字符串搜索符合正则的内容,搜索到就返回出现的位置(从0开始,如果匹配的不只是一个字母,那只会返回第一个字母的位置)
如果搜索失败就返回 -1
用法:字符串.search(正则)
例子:在字符串中找字母b,且不区分大小写
var str = 'abcdef';
var re = /B/i;
//var re = new RegExp('B','i'); 也可以这样写
alert( str.search(re) ); // 1
match方法
语法:
stringObject.match(searchvalue)
stringObject.match(regexp)
searchvalue:必需。规定要检索的字符串值。
regexp:必需。规定要匹配的模式的 RegExp 对象。如果该参数不是 RegExp 对象,则需要首先把它传递给 RegExp 构造函数,将其转换为 RegExp 对象。
如果 regexp 没有标志 g,那么 match() 方法就只能在 stringObject
中执行一次匹配。如果没有找到任何匹配的文本, match() 将返回 null。否则,它将返回一个数组。
例如:
"186a619b28".match(/\d+/g); // ["186","619","28"]
如果上面的匹配不是全局匹配,那么得到的结果如下:
`["186", index: 0, input: "186a619b28"]`
replace方法
replace 本身是JavaScript字符串对象的一个方法,它允许接收两个参数:
replace([RegExp|String],[String|Function])
第1个参数可以是一个普通的字符串或是一个正则表达式.
第2个参数可以是一个普通的字符串或是一个回调函数.
如果第2个参数是回调函数,每匹配到一个结果就回调一次,每次回调都会传递以下参数:
result: 本次匹配到的结果
1,…9: 正则表达式中有几个(),就会传递几个参数,1 9分别代表本次匹配中每个()提取的结果,最多9个
offset:记录本次匹配的开始位置
source:接受匹配的原始字符串
以下是replace和JS正则搭配使用的几个常见经典案例:
$1$2…表示第几个子表达式
(1)实现字符串的trim函数,去除字符串两边的空格
String.prototype.trim = function(){
//方式一:将匹配到的每一个结果都用""替换
return this.replace(/(^\s+)|(\s+$)/g,function(){
return "";
});
//方式二:和方式一的原理相同
return this.replace(/(^\s+)|(\s+$)/g,'');
};
^s+ 表示以空格开头的连续空白字符,s+$ 表示以空格结尾的连续空白字符,加上() 就是将匹配到的结果提取出来,由于是 | 的关系,因此这个表达式最多会match到两个结果集,然后执行两次替换:
String.prototype.trim = function(){
/**
* @param rs:匹配结果
* @param $1:第1个()提取结果
* @param $2:第2个()提取结果
* @param offset:匹配开始位置
* @param source:原始字符串
*/
this.replace(/(^\s+)|(\s+$)/g,function(rs,$1,$2,offset,source){
//arguments中的每个元素对应一个参数
console.log(arguments);
});
};
" abcd ".trim();
输出结果:
[" ", " ", undefined, 0, " abcd "] //第1次匹配结果
[" ", undefined, " ", 5, " abcd "] //第2次匹配结果
(2)提取浏览器url中的参数名和参数值,生成一个key/value的对象
function getUrlParamObj(){
var obj = {};
//获取url的参数部分
var params = window.location.search.substr(1);
//[^&=]+ 表示不含&或=的连续字符,加上()就是提取对应字符串
params.replace(/([^&=]+)=([^&=]*)/gi,function(rs,$1,$2){
obj[$1] = $2;
});
return obj;
}
/([&=]+)=([&=]*)/gi 每次匹配到的都是一个完整key/value,形如 xxxx=xxx, 每当匹配到一个这样的结果时就执行回调,并传递匹配到的key和value,对应到$1和$2
(3)在字符串指定位置插入新字符串
String.prototype.insetAt = function(str,offset){
//使用RegExp()构造函数创建正则表达式
var regx = new RegExp("(.{"+offset+"})");
return this.replace(regx,"$1"+str);
};
"abcd".insetAt('xyz',2); //在b和c之间插入xyz
//结果 "abxyzcd"
当offset=2时,正则表达式为:(^.{2}) .表示除\n之外的任意字符,后面加{2} 就是匹配以数字或字母组成的前两个连续字符,加()就会将匹配到的结果提取出来,然后通过replace将匹配到的结果替换为新的字符串,形如:结果=结果+str
(4) 将手机号12988886666转化成129 8888 6666
function telFormat(tel){
tel = String(tel);
//方式一
return tel.replace(/(\d{3})(\d{4})(\d{4})/,function (rs,$1,$2,$3){
return $1+" "+$2+" "+$3
});
//方式二
return tel.replace(/(\d{3})(\d{4})(\d{4})/,"$1 $2 $3");
}
(\d{3}\d{4}\d{4}) 可以匹配完整的手机号,并分别提取前3位、4-7位和8-11位,"$1 $2 $3" 是在三个结果集中间加空格组成新的字符串,然后替换完整的手机号。
替换 XXYY---->YYXX
var str = "aabb";
var reg = /(\w)\1(\w)\2/g
console.log(str.replace(reg, "$2$2$1$1"));//bbaa
var str = "aabb";
var reg = /(\w)\1(\w)\2/g
console.log(str.replace(reg, function($, $1, $2) {//replace的第二个参数也可以传进去一个函数,但是如果要用子表达式,那么就必须先传$,然后再传要用的子表达式。
return $2 + $2 + $1 + $1;//子表达式用$取的时候要用加号把它们连接起来
}));//bbaa
替换the-first-name-------->theFirstName
var reg = /-(\w)/g; //因为要操作f和n让它们变成大写,所以要用子表达式的方式传递
var str = "the-first-name";
console.log(str.replace(reg, function($, $1){
return $1.toUpperCase();
}))
3、字符串去重
var str = "aaaaaaaaaaaaaaaaabbbbbbbbbbbbbbbbbbbbbccccccccccccc";
var reg = /(\w)\1*/g;
console.log(str.replace(reg, "$1"));// abc
4、实现从后往前每3个0打个小数点
var str = "10000000000";
var reg = /(?=(\B)(\d{3})+$)/g
//从末尾开始,然后找3个数字连在一起的(\d{3})+$,然后用?=前面为空就表示正向预查空的地方,
//最后添加(\B)是因为如果0的个数为偶数(假设100000000000),那么就会出现.100.000.000.000这样的情况,所以就要加上非单词边界
console.log(str.replace(reg, "."));//10.000.000.000
exec()方法
该方法是专门为捕获组而设计的,其接受一个参数,即要应用模式的字符串,然后返回包含第一个匹配项信息的数组;
在没有匹配项的情况下返回null。返回的数组虽然是Array的实例,但是包含两个额外的属性:index和input
其中index表示匹配项在字符串中的位置,而input表示应用字符串表达式的字符串。
var text = "mom and dad and baby";
var pattern = /mom( and dad( and baby)?)?/gi;
var matches = pattern.exec(text);
console.log(matches.index); //0
console.log(matches.input); //mom and dad and baby
console.log(matches[0]); //mom and dad and baby
console.log(matches[1]); //and dad and baby
console.log(matches[2]); //and baby
对于exec()方法而言,即使在模式中设置了全局标志g,它每次也只是返回一个匹配项。
在不设置全局标志的情况下,在同一个字符串上多次调用exec()方法将始终返回第一个匹配项的信息。
而在设置全局标志的情况下,每次调用exec()则都会在字符串中继续查找新匹配项,如下例子:
var text = "cat, bat, sat, fat";
var pattern1 = /.at/;
var matches = pattern1.exec(text);
console.log(matches.index); //0
console.log(matches[0]); //cat
console.log(pattern1.lastIndex); //0
matches = pattern1.exec(text);
console.log(matches.index); //0
console.log(matches[0]); //cat
console.log(pattern1.lastIndex); //0
var pattern2 = /.at/g;
var matches = pattern2.exec(text);
console.log(matches.index); //0
console.log(matches[0]); //cat
console.log(pattern2.lastIndex); //3
var matches = pattern2.exec(text);
console.log(matches.index); //5
console.log(matches[0]); //bat
console.log(pattern2.lastIndex); //8
IE的JavaScript实现lastIndex属性上存在偏差,即使在非全局模式下,lastIndex属性每次也都在变化。
5.贪婪匹配与非贪婪匹配
贪婪匹配:
贪婪匹配就是仅仅使用单个限定符:*,+,?,n{X},n{X,},n{X,Y}的匹配。
正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配。
非贪婪匹配(懒惰匹配):
非贪婪匹配就是在限定符*,+,?,n{X},n{X,},n{X,Y}之后再添加一个字符?,则尽可能少的重复字符“?”之前的限定符号的重复次数
非贪婪匹配就是匹配到结果就好,就少的匹配字符。
默认是贪婪模式;
在量词后面直接加上一个问号?就是非贪婪模式。
var str = "aaaaaa";
var reg = /a{1,3}?/g;
console.log(str.match(reg));// ["a", "a", "a", "a", "a", "a"]
var str = "aaaaaa";
var reg = /a??/g;
console.log(str.match(reg));// ["", "", "", "", "", "", ""]
var str = "aaaaaa";
var reg = /a*?/g;
console.log(str.match(reg));// ["", "", "", "", "", "", ""]
var str = "aaa aaa";
var reg = / /g;
console.log(str.match(reg));// [" "]
6.正则表达式对象属性
multiline 是一个只读的布尔值,看这个正则表达式是否带有修饰符m。
修饰符m,用以在多行模式中执行匹配,需要配合^ 和 $ 使用,使用^ 和 $ 除了匹配整个字符串的开始和结尾之外,还能匹配每行的开始和结尾。
主要用来匹配多行模式
var str="java\nJavaScript";
str.match(/^JavaScript/); //返回null
var str="java\nJavaScript";
str.match(/^JavaScript/m); //匹配到一个JavaScript
var reg=/JavaScript/;
reg.multiline; //返回false
var reg=/JavaScript/m;
reg.multiline; //返回true
lastIndex
lastIndex:是一个可读/写的整数,如果匹配模式中带有g修饰符,这个属性存储在整个字符串中下一次检索的开始位置,这个属性会被exec( ) 和 test( ) 方法用到。
注:此属性需要单独说明,在exec和test方法下会用到并且改变正则对象的该属性值。
source
source:是一个只读的字符串,包含正则表达式的文本。
var reg = /Abc/;
reg.source; //返回 Abc
global
global:是一个只读的布尔值,看这个正则表达式是否带有修饰符g。
修饰符g,是全局匹配的意思,检索字符串中所有的匹配。
var str = "JavaScript";
str.match(/JavaScript/); //只能匹配一个JavaScript
var str = "JavaScript JavaScript";
str.match(/JavaScript/g); //能匹配两个JavaScript
var reg = /JavaScript/;
reg.global; //返回 false
var reg = /JavaScript/g;
reg.global; //返回 true
ignoreCase
ignoreCase:是一个只读的布尔值,看这个正则表达式是否带有修饰符i。
修饰符i,说明模式匹配是不区分大小写的。
var reg = /JavaScript/;
reg.ignoreCase; //返回 false
var reg = /JavaScript/i;
reg.ignoreCase; //返回 true
var reg = /JavaScript/;
reg.test("javascript"); //返回 false
var reg = /JavaScript/i;
reg.test("javascript"); //返回 true
支持正则表达式的 String 对象的方法
字符串replace的局限性就在于这,这就需要与正则表达式相结合完成替换
var str = "aa";
console.log(str.replace("a","b"));//ba
var reg = /a/ //没有g它也是匹配到了一个就停止了。
var str = "aa";
console.log(str.replace(reg,"b"));//ba
var reg = /a/g
var str = "aa";
console.log(str.replace(reg,"b"));//bb
7.分组和反向引用一个子表达式里面的内容
分组又称为子表达式,首先一个子表达式是用()表示的。
当一个正则表达式被分组之后,每一个组被自动赋予一个组号,该组号可以代表该组的 表达式。
1.匹配XX的片段
var str = "aaaa";
var reg = /(a)\1/g //\1就表示反向引用第一个子表达式(a)的内容
console.log(str.match(reg));//["aa", "aa"]
2.匹配XXXX的片段
var str = "aaaabbbb"; //\1\1\1就表示三次反向引用第一个子表达式(\w)的内容
var reg = /(\w)\1\1\1/g
console.log(str.match(reg));// ["aaaa", "bbbb"]
3.匹配XXXX的片段
var str = "aaaabbbb";
var reg = /(\w)\1\1\1/ //没有g全局搜索就会匹配到了之后就会停止
console.log(str.match(reg));//["aaaa", "a", index: 0, input: "aaaabbbb", groups: undefined]
console.log(reg.exec(str));//["aaaa", "a", index: 0, input: "aaaabbbb", groups: undefined]
var str = "aaaabbbb";
var reg = /(\w)\1\1\1/g
console.log(str.match(reg)); //["aaaa", "bbbb"]
console.log(reg.exec(str));//["aaaa", "a", index: 0, input: "aaaabbbb", groups: undefined]
4.匹配XXYY的形式
var str = "aabbbbcdfsf";
var reg = /(\w)\1(\w)\2/g //\1反向引用第一个子表达式,那么\2就表示反向引用第二个子表达式,还可以有\3,\4,\5........表示反向引用第3,4,5个子表达式的内容
console.log(str.match(reg));// ["aabb"]
var str = "aabbbbcdkkoo";
var reg = /(\w)\1(\w)\2/g
console.log(str.match(reg));// ["aabb", "kkoo"]
var str = "aabbbbcdfsf";
var reg = /(\w)\1(\w)\2/ //没有全局搜索用str.match()就会出现返回子表达式的内容还有一些其他的信息。
console.log(str.match(reg));// ["aabb", "a", "b", index: 0, input: "aabbbbcdfsf", groups: undefined]
没有全局搜索g用str.match()就会出现返回子表达式的内容还有一些其他的信息。
无论有没有g用reg.exec()都会出现返回子表达式的内容还有一些其他的信息,因为这是exec()方法 的特性。
分组不但可以使用数字作为组号,而且还可以使用自定义名称作为组号。
1.以下两个正则表达式都是将分组后的子表达式w+命名为“word”.
(?\w+)
(? ‘word’ \w+)
2.因此,正则表达式\b(\w+)\b\s+\1\b和以下正则表达式等价,它们都匹配重复出现的单词。
\b(?\W+)\b\s+\k\b
3.以下正则表达式和正则表达式\b\w*(\w+)\1\b等价,它也是匹配以两个重复字符结尾的单词。
\b\w* (?\w+)\k\b
4.分组子表达式(?)将元字符括在其中,并强制正则表达式引擎记住该子表达式匹配,同时使用“name”对该匹配进行命名。
反向引用\k使引擎对当前字符和以名称“name”存储的先前匹配字符进行比较,从而匹配具有重复字符的字符串。
8.优先级顺序
9.断言
零宽断言
匹配宽度为零,满足一定的条件/断言。
零宽断言用于查找在某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们像\b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言),因此它们也被称为零宽断言。
断言用来声明一个应该为真的事实。正则表达式中只有当断言为真时才会继续进行匹配
先行断言(零宽度正预测先行断言)
表达式:(?=表达式)
表示匹配表达式前面的位置
先行断言的执行步骤是这样的先从要匹配的字符串中的最右端找到第一个ing(也就是先行断言中的表达式)然后 再匹配其前面的表达式,若无法匹配则继续查找第二个ing 再匹配第二个 ing前面的字符串,若能匹配 则匹配
.*(?=d) 可c以匹配abcdefghi 中的abc
后发断言(零宽度正回顾后发断言)
表达式: (?<=表达式)
表示匹配表达式后面的位置
后发断言跟先行断言恰恰相反 它的执行步骤是这样的:
先从要匹配的字符串中的最左端找到第一个abc(也就是先行断言中的表达式)然后 再匹配其后面的表达式,
若无法匹配则继续查找第二个abc 再匹配第二个abc后面的字符串,若能匹配 则匹配
例如(?<=abc).* 可以匹配abcdefg中的defg
负向断言
负向零宽先行断言 :(?!表达式)
负向零宽后发断言:(?<!表达式)
负向零宽断言 (?!表达式) 也是匹配一个零宽度的位置,不过这个位置的“断言”取表达式的反值,
例如 (?!表达式) 表示 表达式 前面的位置,如果 表达式 不成立 ,匹配这个位置;
如果 表达式 成立,则不匹配:同样,负向零宽断言也有“先行”和“后发”两种,负向零宽后发断言为 (?<!表达式)
- 上一篇:ES5、ES6对象合并方法大全
- 下一篇:php发送post请求方法大全附源码
精品好课

2021年最新Vue2+Vue3+ES6+TypeScript和uni-app开发微信小程序从入门到实战视频教程,本课程教你如何快速学会VUE和uni-app并应用到实战,教你如何解决内存泄漏,常用UI库的使用,自己...
jquery视频教程从入门到精通,课程主要包含:jquery选择器、jquery事件、jquery文档操作、动画、Ajax、jquery插件的制作、jquery下拉无限加载插件的制作等等......
HTML5基础入门视频教程,教学思路清晰,简单易学必会。适合人群:创业者,只要会打字,对互联网编程感兴趣都可以学。课程概述:该课程主要讲解HTML(学习HTML5的必备基础语言)、CSS3、Javascript(学习...
React是前端最火的框架之一,就业薪资很高,本课程教您如何快速学会React并应用到实战,对正在工作当中或打算学习React高薪就业的你来说,那么这门课程便是你手中的葵花宝典。
React是目前最火的前端框架,就业薪资很高,本课程教您如何快速学会React并应用到实战,教你如何解决内存泄漏,常用UI库的使用,自己封装组件,正式上线白屏问题,性能优化等。对正在工作当中或打算学习React高薪就...
VUE是目前最火的前端框架之一,就业薪资很高,本课程教您如何快速学会VUE+ES6并应用到实战,教你如何解决内存泄漏,常用UI库的使用,自己封装组件,正式上线白屏问题,性能优化等。对正在工作当中或打算学习VUE高薪就...
适用人群1、有html基础2、有css基础3、有javascript基础课程概述手把手教你如何开发属于自己的HTML5视频播放器,利用mp4转成m3u8格式的视频,并在移动端和PC端进行播放支持m3u8直播格式,兼容...
React和VUE是目前最火的前端框架,就业薪资很高,本课程教您如何快速学会React和VUE并应用到实战,教你如何解决内存泄漏,常用库的使用,自己封装组件,正式上线白屏问题,性能优化等。对正在工作当中或打算学习Re...